Google Search Console: SEO Guide to the Index Coverage Report

Whether you want to check your website’s indexation status or identify why Google hasn’t indexed certain URLs, Google’s Index Coverage Report—introduced with the new version of Google Search Console in January 2018—is an essential tool for understanding and resolving indexing issues.
In this article, discover how to leverage the Index Coverage Report to improve your website SEO and, subsequently, increase your visibility on Google.
How to access Google’s Index Coverage Report?
To access the Index Coverage Report, log into your Google Search Console account, select a property, then navigate to the Coverage tab on the left-hand side panel under the Index section.
Access Google’s Index Coverage Report under the Coverage tab on your navigation panel
Once inside, you can select whether you want to view All known pages or All submitted pages in the upper left-hand corner of the report. All known pages is the default view option showing you all of your URLs Google has crawled, while All submitted pages only displays URLs that you submitted via an XML sitemap.
Google Index Coverage Report: Choose to view ‘All known pages’ or ‘All submitted pages’
Google Index Coverage Report: URL Statuses
Google’s Index Coverage Report categorizes URLs by four different statuses:
- Error: URLs that could not be indexed due to errors like 404-status codes or soft 404 pages
- Valid with warnings: URLs that have been indexed but contain non-critical errors that you may want to review
- Valid: URLs that have been successfully indexed
- Excluded: URLs that haven’t been indexed because Google received a directive not to from your site, like a noindex meta tag or canonical tag
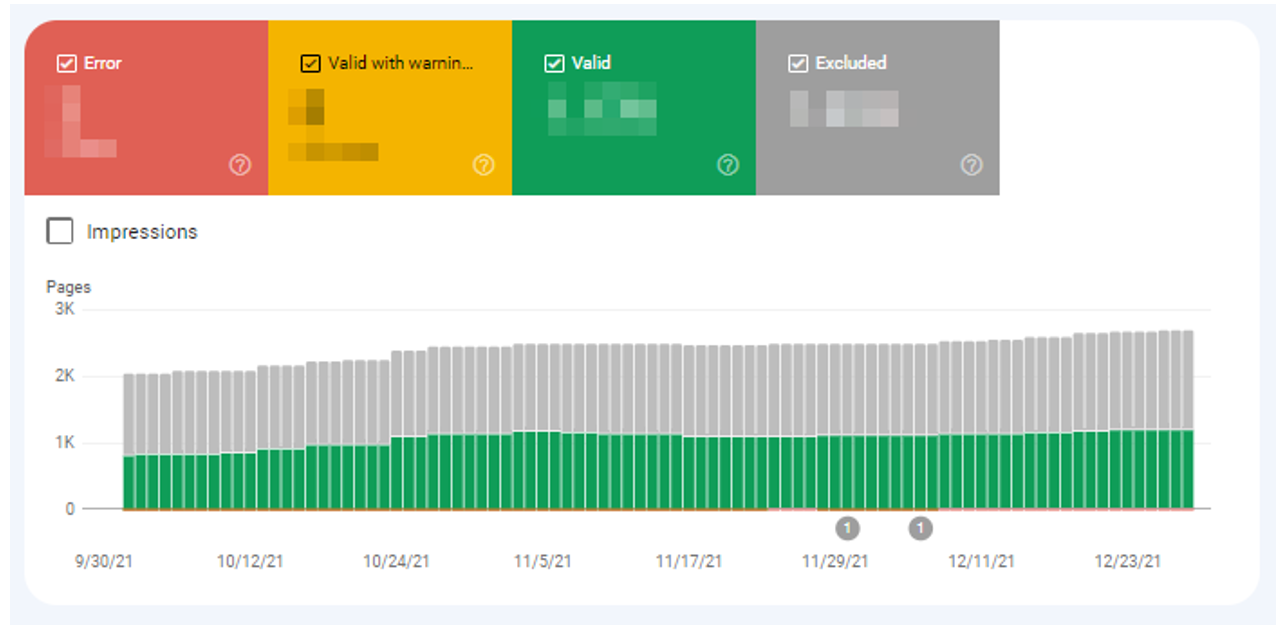
Google Index Coverage Report: Four URL status categories
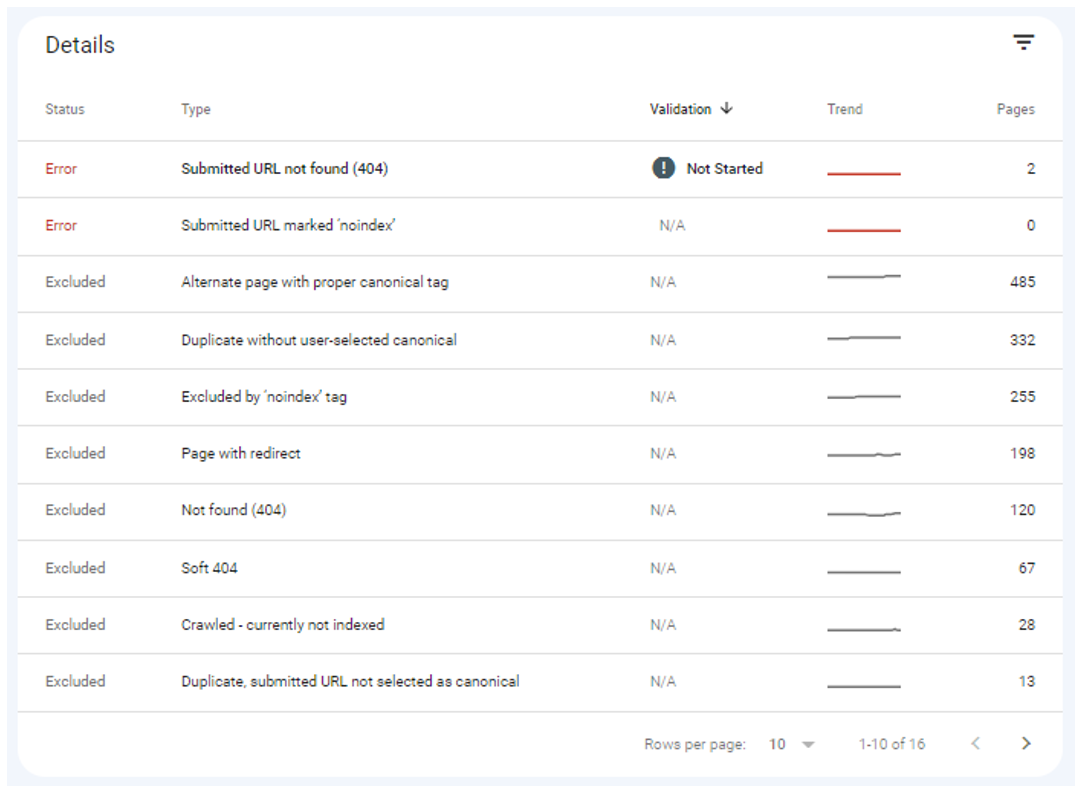
Google Index Coverage Report: Error details
Each of these categories also has different types of errors or warnings, including:
URL Status Category: Error
URLs showing Error are those that could not be indexed due to an error encountered by Google when trying to access your page.
Note: Any errors involving a submitted URL means Google encountered them from URLs submitted for indexing via an XML sitemap. To avoid this, always ensure your XML sitemap only contains indexable URLs.
Server Error (5xx)
Server errors refer to pages that return a 5xx error to Google, like a 502 bad gateway error or 503 service unavailable error.
How to resolve server errors (5xx)?
To fix server errors, you should first identify the server error type and contact your server administrator to resolve them or check if any recent upgrades or changes to your site caused them. Note that server errors are often temporary due to an overloaded server.
For more information, check out Google’s guide on fixing server errors.
Redirect Error
A redirect occurs when a search engine bot is directed from an old URL to a new one. In doing so, Google may potentially encounter some of these redirect issues:
- Redirect loops, which are infinite cycles of redirects caused by URLs redirecting to one another (e., ‘URL A’ redirects to ‘URL B’, which in turn redirects back to ‘URL A’)
- Redirect chains occur when there is more than one redirect between the initial URL and final destination URL (e., ‘URL A’ redirects to ‘URL B’, which then redirects to ‘URL C’)
- Redirects to URLs that are too long
- Wrong or empty URLs found in the redirect chain
How to resolve redirect errors?
- To resolve redirect loops, determine the correct destination page and ensure it is the final redirect.
- To resolve redirect chains, redirect your initial URL directly to your final destination URL.
Submitted URL Blocked by Robots.txt
Robots.txt is a file with instructions directing search engine bots in how they should crawl your website. If you’ve encountered the error submitted URL blocked by robots.txt, this means you submitted a URL to Google for crawling and indexation while signaling it to do otherwise in your robots.txt file.
How to resolve submitted URL blocked by robots.txt issues?
- If your URL should be indexed, update your robots.txt file to remove any disallow directives.
- If your URL should not be indexed, remove them from your XML sitemap.
Submitted URL Marked ‘Noindex’
A noindex directive prevents a page from getting indexed. Hence, submitted URL marked ‘noindex’ errors can arise when you submit a URL for indexation via an XML sitemap but it contains a noindex directive either in the HTML source or HTTP header.
How to resolve submitted URL marked ‘noindex’ issues?
- If your URL should be indexed, remove any noindex directives from your HTTP header.
- If your URL should not be indexed, remove them from your XML sitemap.
Submitted URL Not Found (404)
A 404 HTTP status code indicates that a requested page could not be found because it was deleted or moved.
How to resolve submitted URL not found (404) issues?
- If your page was designed to be a 404 page, remove it from your XML sitemap to prevent Google from indexing it.
- If your URL is not supposed to be a 404 page, restore the page’s content or implement a 301 redirect to the next-most relevant page.
Submitted URL Seems to be a Soft 404
Soft 404s are pages in your XML sitemap that return 200 HTTP status codes but display what looks like 404-page content to users. This is a bad practice that confuses Google crawlers and hurts your SEO.
How to resolve submitted URL seems to be a soft 404 issues?
- If your URL is supposed to be a 404 page, ensure it returns a 404 HTTP status code from the server and is removed from your XML sitemap.
- If your URL is not meant to be a 404 page, ensure its contents do not contain any 404-page messaging.
Submitted URL Returned 403
A 403 HTTP status code indicates a webpage deliberately set to restrict public access.
How to resolve submitted URL returned 403 issues?
- If your URL should be made public, remove any 403 HTTP status codes.
- If your URL should not be publicly available, remove it from your XML sitemap.
URL Status Category: Valid with Warnings
URLs with valid with warning statuses do not have indexation errors but have lower ranking potential, so it’s a good idea to review them.
Indexed, Though Blocked by Robots.txt
This error occurs when Google manages to find—and index—your URL from external links even though your robots.txt file has blocked it from doing so.
How to resolve indexed, though blocked by robots.txt issues?
- If your URL should be indexed, update your robots.txt file to remove any disallow directives.
- If your URL should not be indexed, insert a noindex directive in the HTTP response header.
Page Indexed Without Content
This error occurs when Google has indexed your URL but could not find any content on it, usually due to:
- Cloaking, which occurs when the content you serve to search engines differs from that to human users (e.g., serving a page of HTML text to search engines, while showing a page of images to users)
- Google being unable to render your page
- Google being unable to index your page due to its format
- Google indexing an empty page that you published
How to resolve page indexed without content issues?
Firstly, review pages with this error and double-check if they are missing any content. If not, use Google’s URL Inspection Tool to learn how Googlebot views your pages and request it to re-index your page.
WANT DIGITAL INSIGHTS STRAIGHT TO YOUR INBOX?
URL Status Category: Valid
Valid pages comprise those that Google has correctly indexed. But it is still best practice to check for URLs—like 404 pages—that do not need to be indexed.
Submitted and Indexed
These pages have been submitted via an XML sitemap and are indexed by Google.
Indexed, Not Submitted in Sitemap
These pages were not submitted via an XML sitemap, but Google has still found and indexed them.
How to resolve indexed, not submitted in sitemap issues?
- If your URL should be indexed, add it to your XML sitemap.
- If your URL should not be indexed, insert a noindex directive in the HTTP response header.
URL Status Category: Excluded
The excluded status category of the coverage report contains URLs that have not been indexed by Google.
You may notice parallels between the issues highlighted here and those from the previous sections. However, the main difference is that Google has registered these “excluded” URLs as excluded deliberately as a directive from the website rather than by error, even though that might not always be the case.
Excluded by ‘Noindex’ Tag
These pages were not submitted for indexing but were still found by Google. However, it could not index them due to noindex directives in the HTML source or HTTP header.
How to resolve excluded by ‘noindex’ tag issues?
- If your URL should be indexed, remove any noindex directives and include it in your XML sitemap.
- If your URL should not be indexed, ensure no internal links point to it.
Blocked by Page Removal Tool
These pages do not appear on Google’s search results due to URL removal requests, which temporarily hide URLs from its bots—but there is every chance they might index them again after 90 days.
How to resolve blocked by page removal tool issues?
If your URL should not be indexed, insert a noindex directive in the HTTP header to permanently block it from being indexed.
Blocked by Robots.txt
These pages were not submitted for indexing and are blocked by your robots.txt file. Simultaneously, Google did not receive signals strong enough to warrant indexing them, otherwise, they would fall under another error: Indexed, though blocked by robots.txt.
How to resolve blocked by robots.txt issues?
- If your URL should be indexed, update its robots.txt file to remove any disallow directives.
- If your URL should not be indexed, insert a noindex directive in the HTTP header to permanently block it.
Blocked Due to Unauthorized Request (401)
These pages cannot be accessed or crawled by Google as it received a 401 HTTP status code, which signifies a failed authentication. This usually occurs when pages are still in a staging environment or are password-protected.
How to resolve blocked due to unauthorized request (401) issues?
- If your URL should be public, ensure authorization is not required to access it.
- If Google indexed your staging environment, investigate how it managed to find your pages—i.e., whether via internal or external links. You should prevent Google from indexing pages in a staging environment as they are still a work-in-progress.
Blocked Due to Access Forbidden (403)
Like in the submitted URL returned 403 error, these pages could not be accessed by Google because it received a 403 HTTP status code—the only difference being that, in this case, they were not submitted via an XML sitemap.
How to resolve blocked due to access forbidden (403) issues?
- If your URL should be public, remove any 403 HTTP status codes.
- If your URL should not be public, insert a noindex directive to permanently block it.
Blocked Due to Other 4xx Issue
These pages are inaccessible to Google as a 4xx HTTP response code—other than a 401, 403, or 404 response code—was received. This can happen when Google detects issues like a malformed URL, which returns a 400 HTTP response code.
How to resolve blocked due to other 4xx issues?
Use Google’s URL Inspection Tool to uncover the underlying issue in your page:
- If your URL should be indexed, resolve the identified 4xx issue and submit your URL to your XML sitemap.
- If your URL should not be indexed, no action is required.
Crawled–Currently Not Indexed
These pages have been crawled—but not yet indexed—by Google. This can happen if the page URLs were just discovered and pending indexation or simply because Google skipped them due to their lack of content or internal links.
How to resolve crawled—currently not indexed issues?
You should rectify this issue immediately if it affects any of your important pages:
- If you recently published your important pages, Google should index them soon.
- If Google has not indexed your important pages even though they were published a while ago, optimize them with better quality content and internal links.
Discovered—Currently Not Indexed
These pages have been discovered—but not yet crawled or indexed—by Google.
How to resolve discovered—currently not indexed issues?
Google will usually crawl and index your discovered—currently not indexed pages soon. But if you notice more and more URLs being affected by this error, your website might be facing a crawl budget issue.
To fix this, you should review the list of affected URLs and identify pages that Google should not crawl. For example, if you notice many non-canonical URLs, you can set up a disallow directive on the robots.txt file for these pages to prevent Google from crawling them.
Alternate page with proper canonical tag
Canonical tags help prevent duplicate content issues by indicating the URL of the original copy of a page. Pages listed under this error are duplicates of other pages that have already been canonicalized.
How to resolve alternate page with proper canonical tag issues?
If your URL should not be canonicalized, switch to a self-referencing canonical tag.
Duplicate Without User-Selected Canonical
These pages were identified as duplicates by Google and not yet canonicalized to the original copy. Google will not index these pages as long as it continues viewing them as duplicated or unoriginal versions of another page.
How to resolve duplicate without user-selected canonical issues?
- You should review any duplicated pages detected on your website and choose their appropriate canonical versions.
- If your URL should not be indexed, insert a noindex directive to permanently block it.
Duplicate, Google Chose Different Canonical Than User
Although you’ve set a canonical tag for these pages, Google has ignored it and selected another page as the canonical, which can occur with websites that span across different languages and share similar or thin content.
How to resolve duplicate, Google chose different canonical than user issues?
- If you deem Google’s overriding canonical page selection as correct, update your canonical tags to reflect it.
- If you deem Google’s overriding canonical page selection as incorrect, you should investigate the reasoning behind its decision—does the page comprise more links and high-quality content? If so, you can optimize your original canonical page to match—or one-up—that selected by Google.
Duplicate, Submitted URL Not Selected as Canonical
These pages have been submitted via an XML sitemap but do not have proper canonical tags set up, leading to Google automatically selecting the canonical URL. This is because you have not defined the canonical URL despite explicitly requesting Google to index it.
How to resolve duplicate, submitted URL not selected as canonical issues?
Add proper canonical tags that point to the preferred version of the URL.
Not Found (404)
These are 404 pages that were not submitted via an XML sitemap but possibly discovered by Google from other websites or pages that previously existed and no longer do.
How to resolve not found (404) issues?
- If your URL should be a 404 page, no action is required.
- If your URL should not be a 404 page, you should either implement a 301 redirect to the next-most relevant page or restore the page’s contents.
Soft 404
How to avoid soft 404 issues?
- If your URL should be a 404 page, configure your server so that it returns a 404 or 410 HTTP status code. Alternatively, you may implement a 301 redirect to the next-most relevant page.
- If your URL should not be a 404 page, modify the content on its page so that they do not resemble 404 pages.
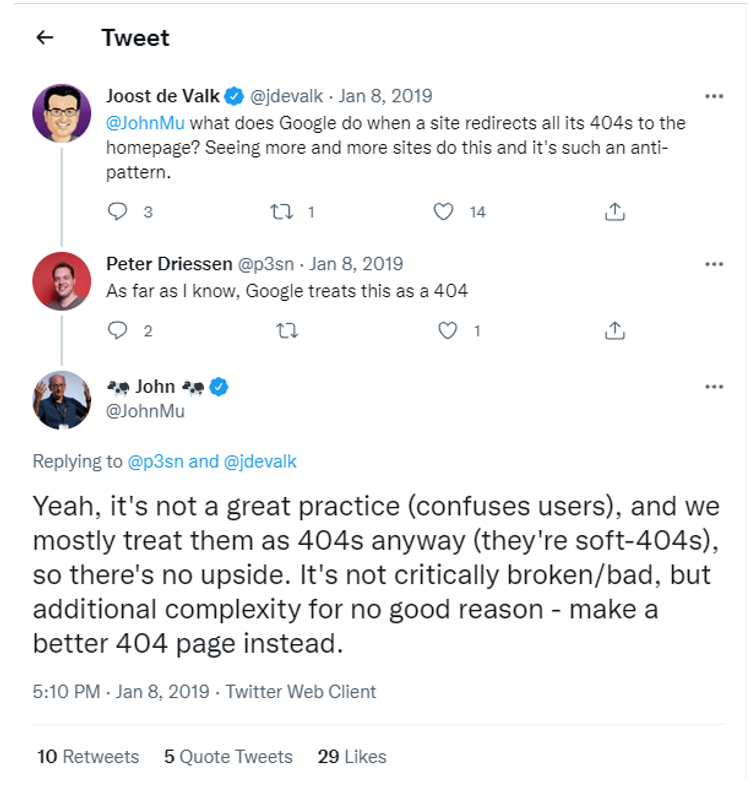
John Mueller’s (Google’s senior webmaster trends analyst) verdict on soft 404 pages
Page With Redirect
These URLs serve as redirects to other pages and, therefore, do not need to be indexed. And although they generally do not require much attention, always ensure you redirect users to the next-most relevant page if you are setting up a permanent redirect.
***
The Index Coverage Report in Google Search Console, which should be checked monthly as a general rule, provides a detailed overview of your website’s crawling and indexing issues—and what you can do to resolve them. To this end, it is critical to prioritize your most important pages for indexation and identify those that should not be indexed.


